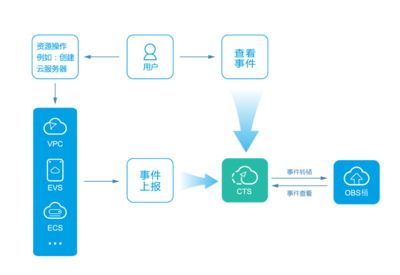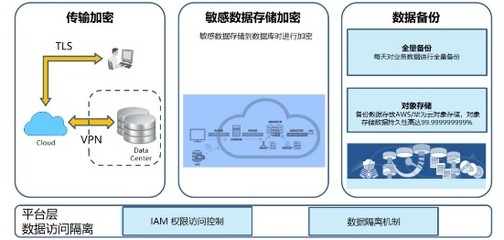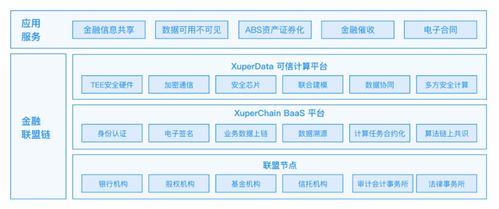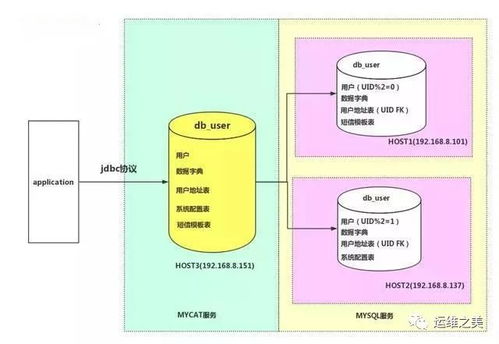
在数字化时代,数据已成为企业决策与业务增长的核心驱动力。对于像链家网这样的大型房产服务平台,高效、精准的搜索与推荐系统是其用户体验和商业成功的关键。而这一切的背后,离不开强大的数据处理与存储服务的坚实支撑。本文将探讨链家网如何通过构建先进的数据处理与存储体系,赋能其搜索优化与推荐策略,实现数据驱动的业务实践。
一、数据处理:从原始数据到业务洞察
链家网每天产生海量的用户行为数据(如搜索记录、浏览轨迹、点击偏好)、房源数据(如位置、价格、户型、图片)、交易数据以及外部市场数据。这些数据来源多样、结构复杂、实时性强。数据处理服务的首要任务是将这些原始数据转化为可供分析和模型使用的干净、一致、高质量的数据资产。
1. 数据采集与整合: 链家通过分布式日志采集系统(如Flume、Kafka)实时收集来自网站、APP、小程序等多端的用户行为日志,并与内部的房源数据库、交易系统等批量数据源进行整合,形成统一的用户-房源交互数据集。
2. 数据清洗与标准化: 房产数据具有地域性强、字段多、非标信息(如户型描述)多的特点。链家利用自然语言处理(NLP)和规则引擎对房源描述进行结构化提取(如将“南北通透三室两厅”解析为明确的属性),并对价格、面积等数值进行异常值检测与校正,确保数据质量。
3. 实时与离线计算: 对于搜索排序和实时推荐,需要毫秒级响应用户的最新兴趣变化。链家构建了基于Flink等流计算引擎的实时数据处理管道,实时计算用户的短期兴趣标签(如“正在关注朝阳区两居室”)。利用Hadoop/Spark等离线计算框架,进行深度的用户画像构建(如长期偏好、购房能力评估)、房源质量分计算以及市场趋势分析,为策略模型提供丰富的特征。
二、数据存储:支撑灵活高效的访问与服务
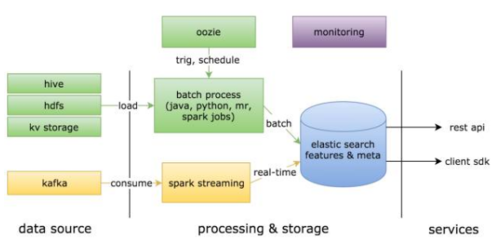
处理后的数据需要被高效、可靠地存储,并支持高并发、低延迟的在线服务访问,以及灵活的分析与模型训练。链家采用了分层、混合的存储架构。
1. 在线服务存储: 为了满足搜索和推荐接口的极低延迟要求(通常要求在几十毫秒内返回结果),链家将核心的特征数据(如用户画像向量、房源向量、热门房源列表)存储在Redis等内存数据库中。将索引化的房源数据存储在Elasticsearch中,以支持地理位置、多字段组合的复杂搜索与排序。关系型数据库(如MySQL)则用于存储交易、用户账户等强一致性要求的核心业务数据。
2. 离线分析与模型训练存储: 海量的历史行为数据、特征数据集以及模型训练样本,存储在HDFS或对象存储(如S3)中,为数据科学家和算法工程师提供大规模数据分析和模型迭代的“数据湖”。数据仓库(如Hive)则用于存储结构化的业务报表和指标数据,支持商业智能(BI)分析。
3. 特征存储与管理: 为了避免特征计算逻辑在训练和上线时的不一致(即“训练-应用偏差”),链家构建了统一的特征平台。该平台将离线和实时计算产生的特征统一注册、存储和管理,确保搜索和推荐模型在线推理时,能够从同一来源准确、快速地获取所需特征。
三、驱动搜索与推荐策略
完善的数据处理与存储服务,直接赋能了链家网搜索与推荐系统的智能化演进。
在搜索优化方面:
- 排序模型: 利用存储的用户历史行为数据和丰富的房源特征,训练深度学习排序模型(如LTR),以优化“相关性”排序,使结果更贴合用户真实意图,而非简单的关键词匹配。
- 查询理解: 通过对海量搜索Query的NLP分析,识别用户的潜在意图(如“学区房”、“近地铁”),并结合用户画像进行意图消歧和结果扩展,提升搜索召回率和准确性。
- 个性化展示: 根据存储在Redis中的实时用户上下文,动态调整搜索结果页的筛选器优先级或信息展示样式。
在推荐策略方面:
- 多场景推荐: 基于统一的用户画像和房源画像,为首页信息流、房源详情页“猜你喜欢”、APP推送等不同场景构建实时推荐服务,实现“千人千面”。
- 协同过滤与向量化召回: 利用存储在数据湖中的亿万级用户-房源交互行为,训练协同过滤模型和Embedding模型,将用户和房源映射到同一向量空间,实现从十亿级全量房源中毫秒级召回最相关的候选集。
- 探索与利用平衡: 通过实时记录和存储新上线房源或冷门房源的曝光与反馈数据,帮助推荐算法更好地平衡“利用”已知用户偏好和“探索”新的潜在兴趣,提升系统整体多样性和用户体验。
###
对于链家网而言,搜索与推荐不仅是功能,更是连接用户与房源的智能中枢。而这一切智能化能力的基石,是一套从采集、处理到存储、服务的完整、高效、可靠的数据技术体系。通过持续投入和优化数据处理与存储服务,链家网不仅提升了当前系统的性能和效果,更重要的是,积累了高质量的数据资产和敏捷的数据能力,为应对未来更复杂的业务场景和更智能的算法应用奠定了坚实基础。数据驱动,在链家已从理念转化为贯穿于数据处理、存储到最终业务价值实现的完整实践闭环。